

Authors:
(1) Li Siyao, S-Lab, Nanyang Technological University;
(2) Tianpei Gu, Lexica and Work completed at UCLA;
(3) Weiye Xiao, Southeast University;
(4) Henghui Ding, S-Lab, Nanyang Technological University;
(5) Ziwei Liu, S-Lab, Nanyang Technological University;
(6) Chen Change Loy, S-Lab, Nanyang Technological University and a Corresponding Author.
Table of Links
![Figure 1: Inbetweening on two source cartoon line drawings of Monkey D. Luffy extracted from ONE PIECE. We compare ourproposed AnimeInbet with state-of-the-art frame interpolation methods VFIformer [14], EISAI [5], FILM [23] and RIFE [6].](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-788304b.png)
Abstract
We aim to address a significant but understudied problem in the anime industry, namely the inbetweening of cartoon line drawings. Inbetweening involves generating intermediate frames between two black-and-white line drawings and is a time-consuming and expensive process that can benefit from automation. However, existing frame interpolation methods that rely on matching and warping whole raster images are unsuitable for line inbetweening and often produce blurring artifacts that damage the intricate line structures. To preserve the precision and detail of the line drawings, we propose a new approach, AnimeInbet, which geometrizes raster line drawings into graphs of endpoints and reframes the inbetweening task as a graph fusion problem with vertex repositioning. Our method can effectively capture the sparsity and unique structure of line drawings while preserving the details during inbetweening. This is made possible via our novel modules, i.e., vertex geometric embedding, a vertex correspondence Transformer, an effective mechanism for vertex repositioning and a visibility predictor. To train our method, we introduce MixamoLine240, a new dataset of line drawings with ground truth vectorization and matching labels. Our experiments demonstrate that AnimeInbet synthesizes high-quality, clean, and B Corresponding author. ∗Work completed at UCLA. complete intermediate line drawings, outperforming existing methods quantitatively and qualitatively, especially in cases with large motions. Data and code are available at https://github.com/lisiyao21/AnimeInbet.
1. Introduction
Cartoon animation has undergone significant transformations since its inception in the early 1900s, when consecutive frames were manually drawn on paper. Although automated techniques now exist to assist with some specific procedures during animation production, such as colorization [22, 32, 10, 39, 4] and special effects [38], the core element – the line drawings of characters – still needs hand-drawing each frame individually, making 2D animation a labor-intensive industry. Developing an automated algorithm that can produce intermediate line drawings from two input key frames, commonly referred to as “inbetweening”, has the potential to significantly improve productivity.
Line inbetweening is not a trivial subset of general frame interpolation, as the structure of line drawings is extremely sparse. Unlike full-textured images, line drawings contain only around 3% black pixels, with the rest of the image being white background. As illustrated in Figure 2, this poses two significant challenges for existing raster-image-based frame interpolation methods. 1) The lack of texture in line drawings makes it challenging to compute pixel-wise correspondence
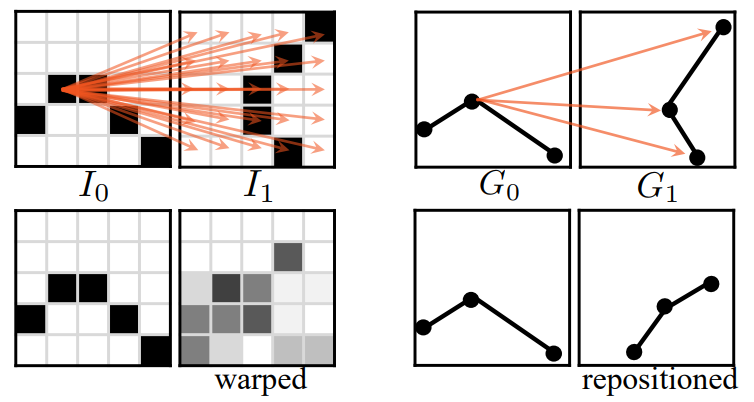
accurately in frame interpolation. One pixel can have many similar matching candidates, leading to inaccurate motion prediction. 2) The warping and blending used in frame interpolation can blur the salient boundaries between the line and the background, leading to a significant loss of detail.
To address the challenges posed by line inbetweening, we propose a novel deep learning framework called AnimeInbet, which inbetweens line drawings in a geometrized format instead of raster images. Specifically, the source images are transformed into vector graphs, and the goal is to synthesize an intermediate graph. This reformulation can overcome the challenges discussed earlier in this paper. As illustrated in Figure 2, the matching process in the geometric domain is conducted on concentrated geometric endpoint vertices, rather than all pixels, reducing potential ambiguity and leading to more accurate correspondence. Moreover, the repositioning does not change the topology of the line drawings, enabling preservation of the intricate and meticulous line structures. Compared to existing methods, our proposed AnimeInbet framework can generate clean and complete intermediate line drawings, as demonstrated in Figure 1.
The core idea of our proposed AnimeInbet framework is to find matching vertices between two input line drawing graphs and then reposition them to create a new intermediate graph. To achieve this, we first design a vertex encoding strategy that embeds the geometric features of the endpoints of sparse line drawings, making them distinguishable from one another. We then apply a vertex correspondence Transformer to match the endpoints between the two input line drawings. Next, we propagate the shift vectors of the matched vertices to unmatched ones based on the similarities of their aggregated features to realize repositioning for all endpoints. Finally, we predict a visibility mask to erase the vertices and edges occluded in the inbetweened frame, ensuring a clean and complete intermediate frame.
To facilitate supervised training on vertex correspondence, we introduce MixamoLine240, the first line art dataset with ground truth geometrization and vertex matching labels. The Anchor frame Anchor 3D mesh Distant frame Figure 3: Geometrized line art in MixamoLine240. 2D endpoints and connected lines are projected from vertices and edges of orinal 3D mesh. Endpoints indexed to unique 3D vertices are matched (marked in the same colors). 2D line drawings in our dataset are selectively rendered from specific edges of a 3D model, with the endpoints indexed from the corresponding 3D vertices. By using 3D vertices as reference points, we ensure that the vertex matching labels in our dataset are accurate and consistent at the vertex level.
In a conclusion, our work contributes a new and challenging task of line inbetweening, which could facilitate one of the most labor-intensive art production processes. We also propose a new method that outperforms existing solutions, and introduce a new dataset for comprehensive training.
This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.