

Authors:
(1) Li Siyao, S-Lab, Nanyang Technological University;
(2) Tianpei Gu, Lexica and Work completed at UCLA;
(3) Weiye Xiao, Southeast University;
(4) Henghui Ding, S-Lab, Nanyang Technological University;
(5) Ziwei Liu, S-Lab, Nanyang Technological University;
(6) Chen Change Loy, S-Lab, Nanyang Technological University and a Corresponding Author.
Table of Links
4. Our Approach


Geometrizing Line Drawings. The process of creating artwork has become largely digital, allowing for direct export in vectorized format. However, for line drawings that only appear in raster images, there are various commercial software and open-source research projects available [40, 36, 15, 12] that can be used to convert the raster images into the required vectorized input format. We will ablate the performance of line vectorization in our experiments.
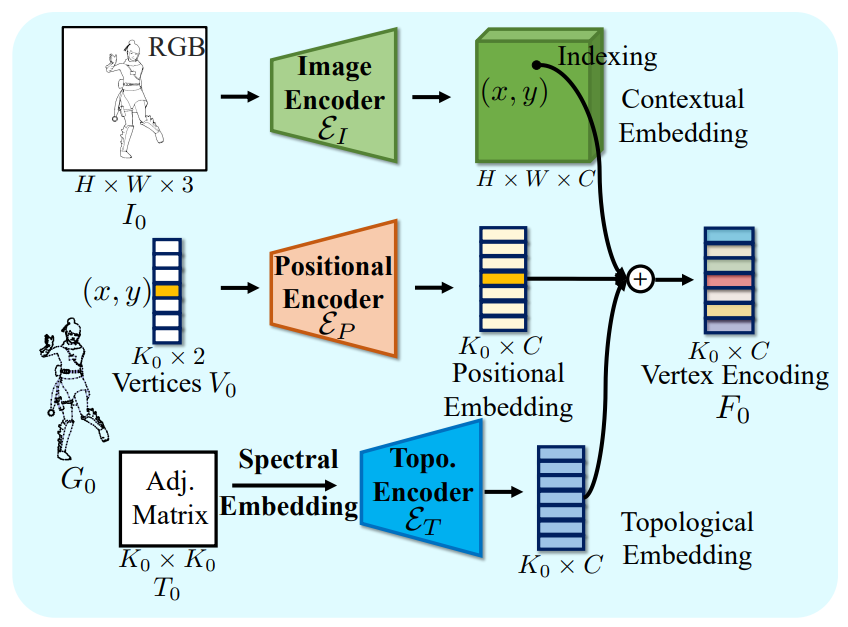
4.1. Vertex Geometric Embedding
Discriminative features for each vertex are desired to achieve accurate graph matching. Line graphs are different from general graphs as the spatial position of endpoint vertices, in addition to the topology of connections, determines the geometric shape of the line. The geometric graph embedding for line art is hence designed to comprise three parts: 1) image contextual embedding, 2) positional embedding, and 3) topological embedding, as shown in Figure 6.

4.2. Vertex Correspondence Transformer
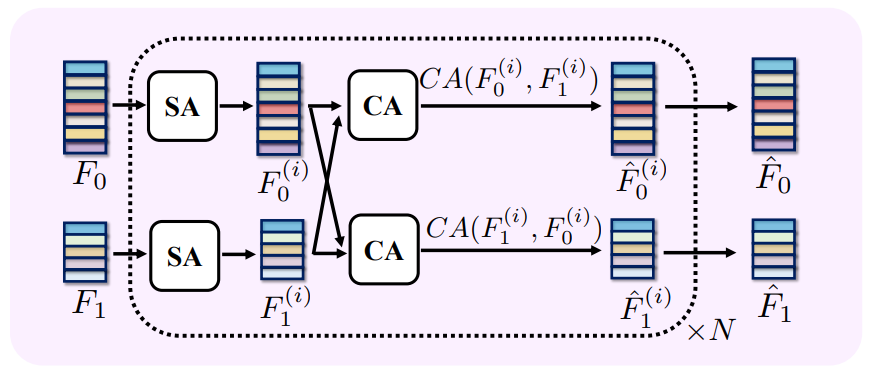
We use geometric features F0 and F1 to establish a vertexwise correspondence between G0 and G1. Specifically, we compute a correlation matrix between vertex features and identify the matching pair as those with the highest value across both the row and the column of the matrix. Prior to this step, we apply a Transformer that aggregates the mutual consistency both intra- and inter-graph.
Mutual Aggregation. Following [24, 31], we employ a cascade of alternating self- and cross-attention layers to aggregate the vertex feature. In a self-attention layer, all queries, keys and values are derived from the single source feature,
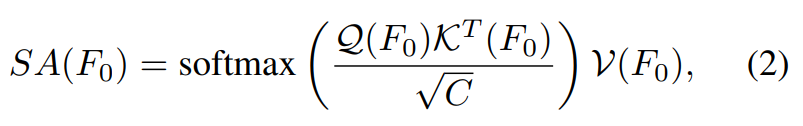

4.3. Repositioning Propagation

4.4. Visibility Prediction and Graph Fusion

4.5. Learning

This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.